Repls and Elk
Crossposted at https://www.lesswrong.com/posts/C5PZNi5fueH2RC6aF/repl-s-and-elk.
In my previous post I talked about read-eval-print loops as providing a type signature for agents. I will now explain how you can quickly transition from this framework to an ELK solution. Notation is imported from that post.
Imagine we have two agents, a human and a strong AI, denoted H and M respectively. They both interact with the environment in lockstep, according to the following diagram.
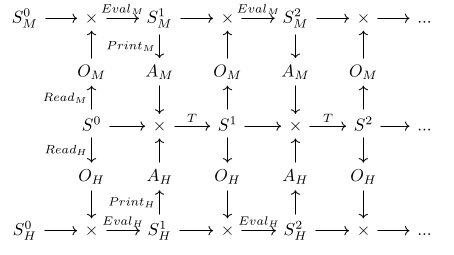
We have the human’s utility function UH:SH→Q, which is defined on the human’s model of reality. We would like to lift UH to a version UM:SM→Q that the machine can use to influence the world in way that is agreeable to the human, which we can do by learning a mapping F : SM→SH and deriving UM=F∘UH.
But we haven’t yet said what properties we want the ontology map F to have. I want to call two concepts sh and sm equal if they act the same with respect to transformation: ∀f. f(sh) = f(sm) → sh = sm. The issue is that since the concepts have different types we cannot feed them as arguments to the same function. So instead let’s say that ∀s:S, EvalH(sh, ReadH(s)) = EvalM(sm, ReadM(s)) → sh = sm. But now we are back to the same problem where we are trying to compare concepts in two different ontologies. But this does give us a kind of inductive step where we can transfer evidence of equality between concept pairs (sh, sm) and (sh’, sm’). I also believe that this kind of a coherence argument is the best we can do, since we are not allowed to peer into the semantic content of particular machine or human states when constructing the ontology map.
Consider the following two graphs.

My intuition is that even if I don’t know the labels of the above graphs, I can still infer that the bottom nodes correspond to each other. And the arrows that I get in the context of ELK are the agents’ Eval transitions, leading to the following commutative diagram specification for F.
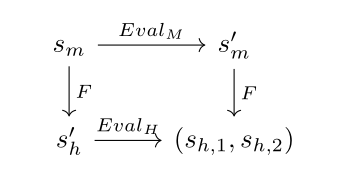
We can learn an ontology map F : SM→SH by minimizing the difference between two paths from a state sm, one in which the machine’s prediction function is used and one in which the human’s prediction function is used. Concretely, I propose minimizing Dist(sh1,sh2) + λ |U(sh1)-U(sh2)| where sh1 = F(EvalM(sm,om)) and sh2 = EvalH(F(sm),oh), Dist is a distance metric in SH, and observations om and oh are generated by the same underlying state S.
If you are interested in getting more detail and why I believe this circumvents existing counterexamples, please check out the full proposal.