Repls
Cross-posted at https://www.lesswrong.com/posts/kN2cFPaLQhExEzgeZ/repl-s-a-type-signature-for-agents.
Read-eval-print loops are used to interact with programming languages as well as in the shell to interact with your computer. I claim that they are a reasonable starting point for reasoning about agents. This is a framing that all but wrote my ELK proposal for me, and has been paying rent in other research domains as well.
Let S be the set of world states, and assume a environment transition function T : S × A → S, where Aₓ is a set of actions. We define an agent X to be a 3-tuple of functions Readₓ, Evalₓ, and Printₓ, where:
- Readₓ is a surjective “abstraction” function of type S → Oₓ, where Oₓ is a type for X’s abstracted observations.
- Evalₓ is a prediction function of type Sₓ × Oₓ → Sₓ, where Sₓ represents the type of X’s internal knowledge of the environment.
- Printₓ is a function from Sₓ to Aₓ, where Aₓ denotes X’s actions on the environment. If there are multiple agents, we assume that an action Aₓ contains one action from each agent.
The environment and agent start in initial states S⁰ and Sₓ⁰, respectively. At each time-step, the agent observes the current state of the environment with its sensors, updates its worldview using its prediction function, produces an action, and then the universe uses that action to produce a next universe state. This process is depicted in the figure below.
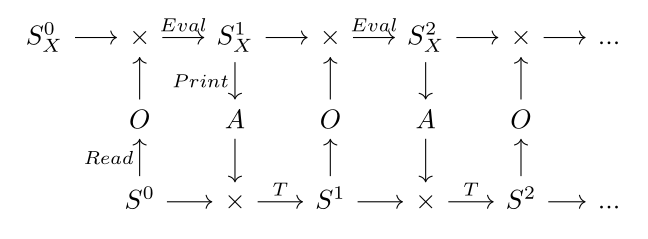
Notice that in the above diagram, the transition functions of the agent and the environment look similar. In fact they are dual, and we can show this by considering the agent’s Readₓ to be the environment’s Print, and the agent’s observation type Oₓ to be the environment’s action type A.
Env := { Print : S → Aₓ, Eval : S × Aₓ → S } Agentₓ := { Printₓ : Sₓ → Aₓ, Evalₓ : Sₓ × A → Sₓ }
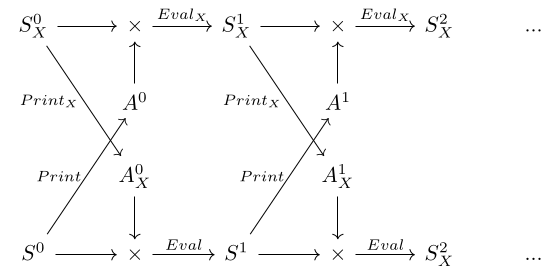
Both the agent and environment start in a given initial state, pick an action based on that state, feed that action to each other’s transition functions, and transition to the next state.
This interaction can be drawn as a game tree where the agent and the environment are selecting which of each other’s next branches to follow.

The agent and environment run in lockstep, each round simultaneously printing and thereby choosing their partner’s next branch. If you want to think of the environment as giving a reward, that reward can be a function of your whole action history, which put you in a particular branch of the physics game tree.
There is much more to say about this setup. I may add future posts on how this leads to an ELK proposal, how it helps bring to light common pitfalls in others’ ELK proposals that I have seen so far, a similar setup in the embedded agency setting, details about nested compositional REPL’s, the connection to polynomial functors and coinductive datatypes, and maybe even a diagrammatic REPL programming language. Please let me know which if any you are interested in and I can post accordingly.
Huge thanks to David Spivak for helping me with these ideas, as well as Gabriel Poesia and John Wentworth.