Conversationism
Crossposted at https://www.lesswrong.com/posts/HpHyERTmsmhDiRHtY/conversationism.
Intro
There seems to be a stark contrast between my alignment research on ontology maps and on cyborgism via Neuralink. I claim that the path has consisted of a series of forced moves, and that my approach to the second follows from my conclusions about the first. This post is an attempt to document those forced moves, in the hope that others do not have to duplicate my work.
Ontology maps are about finding shape semantic-preserving functions between the internal states of agents. Each commutative diagram denotes a particular way of training neural networks to act as conceptual bridges between a human and AI. I originally started playing with these diagrams as a way of addressing the Eliciting Latent Knowledge problem. Erik Jenner has been thinking about similar objects here and here.
Cyborgism via Neuralink is about using a brain-computer interface to read neural activation and write those predictions back to the brain, in the hope that neuroplasticity will allow you to harness the extra compute. The goal is to train an artificial neural network with a particularly human inductive bias. Given severe bandwidth constraints (currently three thousand read/write electrodes), the main reason to think this might work is that the brain and the transistor-based brain predictor are being jointly trained – the brain can learn to send inputs to the predictor such that the predictions are useful for some downstream task. In other words, both the brain and the neural prosthesis are trained online. Think of predicting the activations of a fixed neural network given time series data (hard) versus the same task, but you pass gradients with respect to the base neural network’s final loss through the bandwidth bottleneck into the predictor (less hard).
In the section “An Alternative Form of Feedback”, I introduce a vision of alignment that takes communication bandwidth as fundamental, and I sketch out how one might amplify human feedback on AI via conversation. I might recommend reading that section more than the “TLDR – My Conceptual Path” section.
TLDR – My Conceptual Path
I started thinking about ontology maps in the context of ELK, because ontology maps can translate the AI’s beliefs about the diamond’s location into the corresponding human beliefs. Over time I stopped thinking about aligning an external agent that is super-intelligent and has contrary goals to your own, and instead I thought more about adding compute capacity to yourself/merging with the AI. The former seems somewhat doomed, and in the context of ELK I have come to feel like the human simulator problem is basically unsolvable if you take the aligning external agent point of view. In this document I will go through a series of ontology map training procedures and briefly note on their properties and problems. I will end up at a training procedure that basically looks like the shape of learning to me, and describes how to write the software for Neuralink to leads to a human-AI symbiosis. In bullets:
- Various training procedures for human/AI symbiosis correspond to differently shaped commutative diagrams.
- These commutative diagrams have importantly different alignment properties.
- The diagram that makes the most sense is about agents trying to predict each other.
- These various diagrams don’t address ELK-style human simulator issues.
- Instead of building and/or aligning a separate superintelligence, we should focus on augmenting a human into superintelligence.
Ontology Maps
The broad intuition is that given two state machines representing agents I would like to find a map between them that preserves as much structure as possible. Intuitively I am trying to find a fuzzy homomorphism between graphs. Suppose an agent is defined as a set of states and a transition function on those states. Namely, suppose we have a human agent with state type SH and transition function TH:SH→SH and an AI denoted SMand TM:SM→SM, where M stands for machine. We could train a functionF:SM→SH and G:SH→SM that minimize the distance between TM and F;TH;G, where “;” represents forward composition. This is depicted by the following commutative diagram.
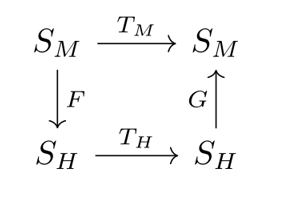
However, this set-up as an alignment strategy would expose us to the risk of steganography. The loss on F and G could be minimized by encoding extraneous information into the belief state SH of the human (such as some random bits about the location of a moon of Jupiter) which TH would not modify. Then G could reconstruct the original SM by interpreting those extra bits, and then use TM to achieve zero loss. I thought at the time that this steganography was being caused by the extra degree of freedom in learning both F and G. So then I thought about the following diagram:
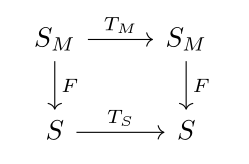
We can call this picture the abstraction diagram. For this intuition think of TM as quantum mechanics and TH as Newtonian mechanics. F abstracts the state of the worlds into coarse statements about mass and energy and such, so that propagating the system forward with quantum and Newtonian transitions commute.
So now we are only learning one function F:SH→SH, which may prevent steganography. And it has a certain intuitive appeal: it could be interpreted as saying two belief states are equal if they have the same relationship to other beliefs. However, I have not yet added any additional structural assumptions to the state set SH, so there is not a natural differentiable distance metric in SH (to my knowledge). So instead we can consider probability distributions ΔSH, use Kullback-Liebler divergence, and this model is now PyTorch ready:
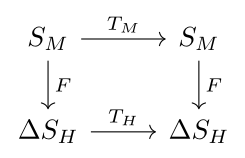
But then I can achieve zero loss by learning an F that maps a state in SM to the uniform probability distribution over SH. So we could add a term in the loss to penalize the average distance between the images of two random states in SH under F. But this is ad-hoc, and what I am really trying to do is preserve the information in agent M when mapping through agent H, which sounds like our first diagram. So why don’t we try a different method to prevent steganography – reversing the directions of F and G (and keeping the probabilistic modification):
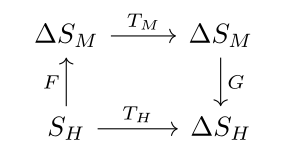
Let’s use an example to illustrate what we want from this diagram. I want an SM,TM that fully captures the partial information from SH,TH. Let SH have 5 elements and let TH cycle between the first three elements and a cycle between the last two elements. We can write TH as the permutation (012)(34). Let SM have six elements and let TH be a 6-cycle (012345). If you haven’t seen this syntax for permutations before, you can just look at the following diagram.
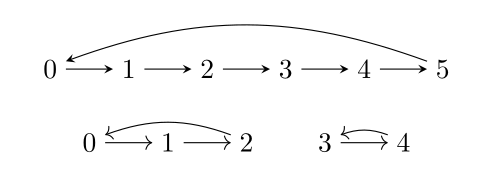
We can run this training algorithm with the following encodings:
- TM is the off-diagonal 6 by 6 matrix
- TH is the 5 by 5 matrix consisting of the off-diagonal 3 by 3 and 2 by 2 matrices
- F is a neural network with 5 inputs and 6 outputs
- G is a neural network with 6 inputs and 5 outputs
Intuitively, I wanted F to become the matrix:

In words, if the state was 0 I would like it to map to uniform distribution of values that are 0 modulo 3. If the state is 3 then I would like it to map to a uniform distribution over values that are 0 modulo 2. This is because I want to be able to use F;TM;G to reconstruct TH as well as possible. But what happens if F and G are nonlinear functions (which is necessary if we want to scale this procedure to non-trivial agents)? Answer: horrible, horrible steganography. If you think of floating points numbers as being real numbers, then F can encode arbitrary information about SH in the particular probabilities that it picks, even if SM only consisted of two states. We could try sampling after taking F, and training with Gumbel-softmax or the reparameterization trick or with REINFORCE, or something. But this feels kind of ad-hoc and gross again.
So the only kind of information bottleneck guarantees that we are going to get when routing through TM are based on the capacities/vc-dimension/inductive biases of F, TM, and G. At this point, we might as well only consider continuous spaces and let SH and SM always be Rn and Rm for some n and m. Large language models seems to be getting mileage out of tokenizing and embedding everything anyway. So Erik Jenner was right all along, and we can write these diagrams first, and think about what category our diagrams are in later, as long as that category has a distance metric (which R does of course). So let’s strip off the probability symbols and write my favorite diagram.
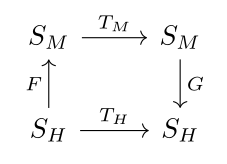
To be clear, at this point we have basically given up on the steganography story. But I think we have arrived at something very nice. I think this diagram is essentially the shape of the learning. Namely, F and G are the glue between you and external computation processes that predict you. For instance, F is typing into the calculator, TM is the calculator running, G is reading the output. Crucially, you must find that it produced the same number that you would have produced yourself.
This is a general process that can be used to parallelize a serial computation. Suppose I have some sequence of instructions in a programming language, such as python.
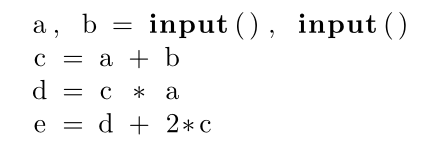
I want to think of this computation as happening continuously in lockstep. The variables “a” and “b” are really more like electrical wires, which always have a voltage, which sometimes changes. The variables “c”, “d”, and “e” are each getting updated each clock cycle with the values from their most recent inputs. An arithmetic circuit with open input wires will also work for this story.
Suppose I also have some extra computers lying around that I want to use to speed up this computation. Among the most naive things I could do is point an extra computer at “e”, and predict the next step in its time-step data by using its previous value, or sampling predictions according to the distribution of what values that variable has taken so far. But you could also imagine giving this extra computer access to time series data of other variables such as “a” and “d”. If the predictor computer is sufficiently accurate, the base computer might accept its predictions and get to next stable state of the system more rapidly. We would save serial compute steps by short-circuiting the intermediate computations. We’d be in an even better situation if the predictor computers could learn which inputs to pay attention to. We’d be in a better situation still if the base computer program could learn when to accept predictions from the prediction.
In this analogy, the original program is TH, and the predictor functions are F;TM;G. Indeed it only makes sense to talk about F;TM;G as opposed to learning a function T′H:SH→SH when there is another pre-existing useful function around, such as pre-trained language model. If TH is some supervisory signal, autoencoders are the special case of this diagram where TM is the identity function. The sparsity of the autoencoder depends on the relative dimension of SH and SM. I sometimes think of transformers as using linear F and G to embed and unembed, and TM here is computation in the residual stream. I would greatly appreciate comments to this post with machine learning instantiations of this structure.
I am thinking of a story where the universe consists of a bunch of functions, and each of these functions is being replaced by faster functions that do the same thing. That same thing is essentially getting to the stable point of the universes dynamics faster – so the functions are replaced by others that are better at eating negentropy. See the figure below for a rough illustration of this.
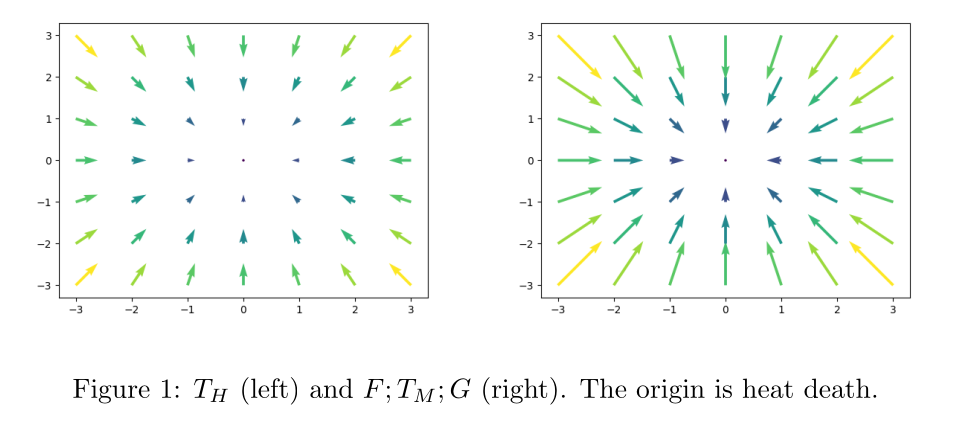
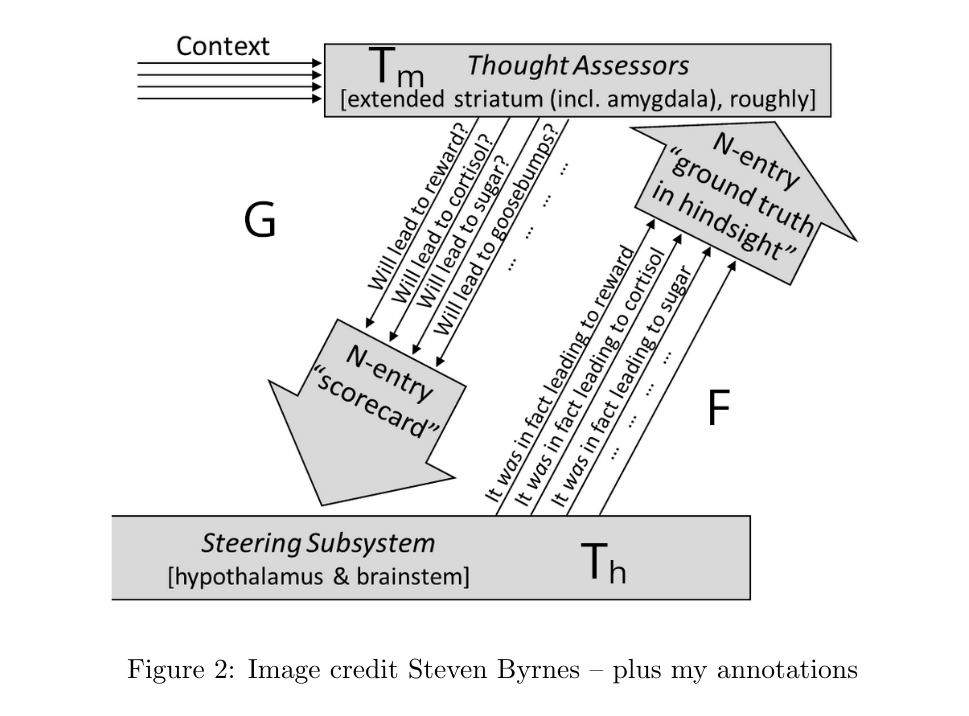
I also think this shape of predictors replacing predictors is like the relationship between the steering and learning subsystems in Steven Byrnes’ Intro to Brain-Like-AGI Safety.
What To Do with the Nice Shape
Ok, so maybe some functions can learn some other functions. Why are we here, and why have I taken up so much of your time to say such an obvious thing? If this is supposed to represent a training loop where the human is represented by TH, don’t you need a version of a human that is in a computer in the first place? Additionally, if uploading actually worked in time, then wouldn’t we already have a win condition for alignment?
My response to the “needing an upload first” concern used to be that TH could be a very partial version of your full transition function, such as the heart rate monitor on your Apple watch, or GPT fine-tuned on your writing. And GPT fine-tuned on your writing is definitely closer to the TH I want to put through this protocol, but I think it is probably not enough to capture what I care about.
So the natural next step here is doing a better job of putting a person in a computer. This is bottlenecked on what kind of data you can use to train a predictive model of a person. So in this post I talk about getting brain activation data via many small electrodes, because this might have a higher change of capturing important aspects of myself for a pseudo-uploading procedure.
I will describe the pseudo-uploading procedure in terms of my diagram. We start with a pretrained model (TM) such as GPT, potentially fine-tuned on pre-existing EEG data. We read brain data via electrode and translate into TM’s latent space using F. TM makes a prediction of the brain’s future activations. G translates that prediction and writes the prediction back into the brain via electrode stimulation. Note that in this story F, TM, and G kind of blend into each other since TM is being trained online.
As I mentioned in the intro, I only expect this to work because the brain is trying to predict the neural prosthesis as the neural prosthesis is trying to predict the brain. So this makes it seem like we are now talking about a conversation:
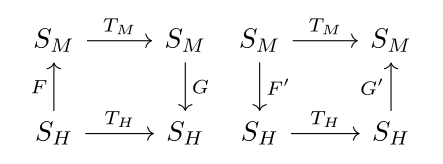
This whole story has essentially been about how to increase the bandwidth between agents, and the answer is something like mutual prediction. Each agent is learning how to write and read to the other agent in order to speed up / parallelize their own computation. These thoughts about commutative diagrams are how I prefer to design the software for Neuralink.
But using only a single “F”, “G” pair for Neuralink seems lopsided and asymmetric. For example, I wanted to train a “predictor” neural network to predict a “base” neural network’s activations. I would do this by training the “base” neural network, and letting gradients propagate back into the “predictor” network. I would prefer if it was that the AI and the human in the loop both had something to gain from the conversation, and learned to call each other as API’s when they desired.
An Alternative Kind of Feedback
Recently, I have been internally debating on whether to label my recent thoughts as a particular flavor of cyborgism, using Conjecture’s terminology. I have come to feel that there is an important distinction I want to make reflecting the bidirectional nature of conversation.
I will sketch a different way to align an AGI than RLHF or conditional pre-training to give a sense of my aesthetic. Raising a child via a yes/no reward signal would be very low bandwidth, not to mention unkind. Instead I could imagine starting with a toddler GPT-J, and training it via minimizing prediction error on conversation with a select set of parents. As it gets older, it can ask to read parts of the internet or chat with particular people from a wider set of less vetted parents. When it reaches school age, it can be trained via conversations with similarly competent language models. This process can potentially be sped up by learning particular F and G’s to speak directly into each other’s latent spaces. At this point it is competent enough to be useful to a broad group of people, who can pay to talk to it. It can use some of that money to pay to talk to particular people and language models, at which point it is a functioning member of society.
The most obvious way that this can go wrong is if the initial high-bandwith parenting via conversation is too expensive. So we could fine-tune GPT on high quality parenting scripts. This GPT-Nanny already seems like a better (higher bandwith) version of feedback than reward modeling of human annotators in RLHF. The role of alignment reaserchers would to push back the pareto-frontier of cost versus annotation quality.
I would like to call this style of approach conversationism, where we especially highlight the creation of a bidirectional relationship and cultural integration of AI. I know the reader is thinking it is naive think that the best way to build a nice AI is to treat it nicely, but I am having trouble imagining any other way. I have more thoughts on the philosophy of this approach, but that will have to wait for another post.
An aside: Parents (and all agents really) can prepend their messages with a secret hash so that the language model knows who it is talking to. It would be unfortunate if someone could easily pretend to be your mom while calling you on the phone.
Some Related Work
The most obvious related work is Erik Jenner’s here and here, linked again for convenience.
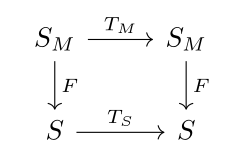
He uses the abstraction diagram from the machine’s state into S, which I am thinking of a general human interpretation language. He also is trying to discover TS jointly with F, if I understand correctly. I labelled the bottom states S to denote a common language between humans (SH for many different values of H). I am thinking more about the prediction ontology map, because I am especially interested in interpretability that works in both directions. I would like to know how to compose individual agents into a super-agent via conversation and communication.
The abstraction ontology map is like viewing one agent’s state as an abstraction of another agent’s state, and various choices of abstraction are discussed in Towards a Unified Theory of State Abstraction for MDPs. This looks similar to bisimulation of labelled transition systems, as well as another that looks like Probabilistic Bisimulation. Other related works include Causal Distillation for Language Models, Approximate Causal Abstractions, and Causal Abstractions of Neural Networks.
Some Light Category Theory
The prediction diagrams form a category:
- An object is a state space and a transition function ⟨S,T:S→S⟩
- The morphisms between objects ⟨S,T:S→S⟩ and ⟨U,V:U→U⟩ are pairs ⟨F:S→U,G:U→S⟩ such that T=F;V;G
- The morphisms are indeed transitive and associative. There are identity morphisms for each object.
The objects are dynamical systems, and I am thinking of an agents as a special kind of dynamical system. The morphisms are choices of read-eval-print loops in the sense of my repl post. It is interesting that this representation allows a single agent to have multiple different ways of interacting with the world. A morphism from A to B semantically means that agent B predicts agent A, or that agent A uses agent B.
Also, if we allow the distinct domains and co-domain in the transition function, then the abstraction diagram category is called the arrow category. And the prediction diagram category is called the twisted arrow category.
A two-sided conversation would correspond to a pair of morphism back and forth between two objects in the twisted arrow category. But having such a pair of morphisms is a very strong condition. So going forward we may want to formalize two agents as communicating in some shared part of their ontologies. I have some thoughts in this direction thanks to @davidad.
Thanks
A very incomplete list of thanks:
- @Victor Lecomte – for pushing me away from the single F story, and back to the F and G story
- @sudo -i – for proof-reading and bouncing these ideas back and forth with me
- @davidad – for telling me names of the categories I have been poking at, and for providing a direction for future theoretical (and hopefully empirical) work
- @Victor Warlop – mentioned to me the idea of thinking of current AI’s as children
- @Erik Jenner – for suggesting that particular category (in the math sense) of the diagram doesn’t matter
- @MalcolmOcean – sketched a view of opening up the AI to interaction with the world via REPLit, and commiserated with me about using an impoverished yes/no training signal
- @Samuel Chen – helped me brainstorm names for the aesthetic I want to cultivate in the alignment community. Pointed out that the limit of high bandwidth communication will create a symbiorganism.
- @Vivek Hebbar – for conversations about whether F and G should be inverses, and suggestions about some probabilistic state space content
- @Aryan Bhattarai – Gave the idea of linear F and G.